不曉得你有沒有想過比起其他食物鏈頂端的其他生物,為何只有人類可以發展高度文明,甚至可以航向宇宙星辰?答案就是典範移轉!本文將會介紹在AI的世界了如何應用這個技術,用最短的時間與最小的資料集,訓練出不錯的AI模型…
前言:
有朋友問我「台灣的中小企業佔了 95%,大家都養不起資料科學家,隨著 AI 的技術愈來愈成熟,難道沒有更容易讓AI普及的方法嗎?」就像你想切入汽車市場,在汽車工業這麼發達的現今,應該不需要從做輪子開始吧?不然純電動車的特斯拉,是怎麼橫空出世的?
其實這個問題,不好回答,但在我心中有三種腳本的答案,方案一叫 Auto ML,要服務的對象是有錢人家的公子爺們;方案二叫AI gallery,是有GPU的開發團隊;方案三叫Transfer Learning,是有RD團隊。
在 Azure Auto ML的解決方案裡,只要你有明確的題目與資料集,完全不需要管 AI流程中的資料整理、特徵工程、演算法選擇、超參數調整…等細節(如果對完整的 AI流程不熟悉可以參考這一篇),就能在 Portal 上輕鬆的一鍵生成模型。因為,雲端平台會在背後以暴力法,高併發的方式幫你嚐試各種排列組合,然後你就可以看報表,決定你要用哪個模型?
在 Azure AI Gallery解決方案裡,除了你需要有明確的題目與資料集之外,你需要對完整的 AI流程有一些概念。因為當你用分類索引的瀏覽或是關鍵字搜尋到適合你的 AI template之後,你還需要有 Azure 訂閱,才能開啟 AI 範本,把資料來源置換成你的 Data set,對流程內的細節以拖拉點選的方案,才能像個花匠一樣修枝潤飾,完成調整超參數或是損失函式選擇的相關動作。
如果上述還不能滿足你,在微軟廣大的AI 生態系中還有 ML.Net, DataBricks …多種解決方案中,除了你需要有明確的題目與資料集之外,你還需要對完整的 AI流程有熟練的規劃與操作能力,並知道 Transfer learning 的原理與運用的方法,例如你要下載由學界知名資料集(Coco, ImageNet…)所訓練出來的模型集(多大規模的模型,例如 ResNet50/101/152…),是要遷移全部 Layer的參數,還是部份 Layer?
何謂遷移式學習?
不曉得你有沒有這樣的經驗,要教一個女生學會騎機車,可以先教她騎腳踏車?在學術界,是先由心理學家投入這樣的研究,接著資訊科學家,開啟了依據遷移的情境(Scenario)、方法(Method)、特徵空間(Feature space)的專門研究,
若你要我下一個定義,就像人類可以舉一反三,只要讓AI 看過足夠的 data,學會低維/中維/高維的 Pattern,它除了可以處理好當前的題目,甚至也可以透過典範移轉的方式,將參數移花接木至另一個 AI模型,處理不同的題目。
在遷移式學習的框架中,由上而下,分別是:Domain, Task, Label, Class,可以是單純的問題;也可以是複雜的問題 Multi-task (例如將貓狗分類器與老虎大象分類器一起訓練)/ Multi-label (例如油電混合車,同時標記被標記汽油車 & 電動車二個 Label)/ Multi-class (例如油電混合車,他同時會預測為汽油車 & 電動車二個分類)的分類問題,透過 shared representation(家貓與老虎都是貓科,資訊可以共享) 一起訓練,來達到省時省力的高效成果。
台大的李宏毅教授就曾經舉過這樣的例子:有一個高手學生,應用了學術界知名影像資料集,做出了貓狗分類器,完成了期中作業並且得到高分。接下來老師又出了期末的作業,他運氣很好!被分到相似的貓狗分類題目,只不過這次的資料集被換成卡通的,於是他透過 Pre-train & Fine tuning 手法,將前一個 AI模型的參數移轉給新的 AI模型,輕易地完成高飛狗(Goofy)與招財貓的辨識,這個叫 Different domain, same task。高手喜歡幫助異性,於是他改了一下程式,也成功地完成女同學被分到的非洲大草原上的大象與老虎的分類器,這個叫 Same domain, different task。
總之,李教授總結了最近國內外的傑出學者的研究成果,依據 Source 的 Data 有標記/無標記,使用與Target 的 data 有標記/無標記,橫跨了監督式/非監督式學習在四個象限中共有數種因應的方法:
| Source data labelled | Source data unlabeled | |
| Target data labelled | 1.Fine tuning 2. Multitask learnin | 5.Self-taught learning |
| Targe data unlabeled | 3.Domain-adversarial training 4. Zero-shot learning | 6.Self-taught clustering |
- Fine tuning:以CNN應用在影像辨識為例,指的是凍結前幾層Layer 參數,只讓此次新的 Data 參與後幾層Layer 的訓練。你可能會問說為何只固定前面幾層?是因為 CNN的學習是有層次的,是由點、線、面慢慢學起來的,不管是辨識動物、植物、礦物,底層都是相同的,要到高階理解時,辨識動物才能用眼睛這種中階物件來區分不同的動物。或者,你可以理解成,我們需要曾經去蹲過少林寺的苦行僧小孩,接著再教他最時尚的高難度動作,然後你就可以開賣太陽馬戲團的票,開心的數鈔票了。
- Multitask learning:顧名思義,MTL就是把多個相關的任務,一起做訓練。在目前大多的 AI應用中,多半都是採用了 Single task 來處理問題。也就是將原本複雜的問題拆解為簡單而相互獨立的子問題,然後再合併其結果,試圖解決複雜的問題。看似合理,卻存在你無法保證獨立子問題彼此不存在不可切割的未爆彈,為此還有一支透過共享中間資訊,專門在處理複雜問題的分支。剛才有提到,又可以細分為多任務、一個物件被標記為多個類別、一個物件被預測為多個類別…
在模型的設計上,則會依據 MTL的 similarity相似性, relationship關聯性, hierrarchy階層關係, benefit效益,分別去選擇 Fully-Adaptive Feature Sharing、Cross-stitch Networks、Low supervision、A Joint Many-task Model、Weighting losses with uncertainty、Tensor factorisation for MTL、Sluice Networks…不同的架構 - Domain-adversarial training:以模型來看,它屬於 Domain-Adversarial Training of Neural Networks (DANN)類型,是用在解決監督式學習遇到沒有 Label 的 Data 的問題。它的原理是應用了生成對抗網路 GAN(常被用在知名電影、三級片、Kuso新聞上變臉的演算法)的手法,來解決 source domain 有 label 但是 target domain 沒有 label 的狀況。但是,在實務中 GAN的本質中,除了需要耗費較多的 GPU成本,在中間調校超參數時也不是那麼直覺且容易的,所以,會被我歸在有錢人的方案。
- Zero-shot learning:目前 ZSL已成功的應用在影像分類、物件偵測、影像生成、語義分類、NLP…等範疇中。在一開始,我就提到過,人類能運用推理來舉一反三,在不需要看過所有生物的情況下,能夠正確地區分出外星人與地球生物的不同。人類,甚至也能將一些分類結果做累加,例如能分辨生物與非生物;能分辨水中、陸地、天上生物,能分辨四足、直立、爬行的陸地生物;就能區分出人類與其他生物的不同。同理,ZSL可以直接對上述的三個分類器透過 Knowledge transfer 的手法,在不需要準備人類照片,就能訓練出一個人類分類器。只要你沒有遇上 domain shift problem, bubness problem, semantic gap 三個罩門。
- Self-taught learning:又稱為 Soft-taught learning,主要是透過非監督式學習來學會特徵值的抽取,然後再將成果繼續用在監督式學習,來解決手邊是沒有 Label 過的 Data問題。例如在Andrew Ng 大師的經典示範中,經過測試在 Minst 手寫數字辨識問題上,原先6分鐘可以達到 95%左右的水準,再加入了 Self-taught learning 手法重新訓練,經過了30分鐘的時間,可以再拉高至 98%。這個範例是先將0~9 切分成 0~4是 LabledSet;5~9是 UnlabledSet故意拿掉。然而在實務上,當你的 Labled 資料很少,就可以去買,如果嫌貴,就去網路上爬蟲,然後配合這個方法來實作。
- Self-taught clustering:基礎於非監督學習中的 Clustering 分群(類聚),這個方法的要求是 Source data 一定要比 Target data 多很多,一但 Source data 足以生成有效的 clusting 時,才能把這個成果移轉到 Target 然後再用 unlabeled 的 data 進行分群
挑戰與回應:
- 要解決的問題:在醫學的應用中,罕見疾病發生的機率就不高了,許多醫師也是在學校學過,真正在臨床遇到時才在書上、網路上找資料來協助判斷當前的病患是否確診?同理,佔台灣最大宗的製造業,在做良率檢驗時,如果遇上了瑕疵的 data 量太少,或是正常與瑕疵的量不成比例,不是透過 Data augumentation(正規化、白化、影像處理) 或是增/減 Data 可以解決的。
註:所謂的影像處理,指的是放大、縮小、裁切偏移、翻轉,甚至是改變比例尺寸、亮度色溫等…手法 - 相同的問題:在傳統的ML中,訓練與測試資料集需要來自於相同的 feature space 特徵空間,換句話說你不能拿國中數學去訓練模型,然後拿高中數學去測試它。因為這二個資料集的 Domain可能是不同的,說的更精準些是 feature space & probability 可能會一樣,但也可能是不一樣;或者是這二個資料集的 Task 可能是不同的,說的更精準些是 label space 標記空間 & object predictive function 目標預測函式 可能會一樣,但也可能是不一樣。同理,除了模型在初始生成有這樣的問題需要被考慮,隨著時空推移,因為主客觀環境的變化,將會出現 Model update 的狀態。就像一份考古題不可能永遠有效,需要被更新…
- 為了解決上述的問題,遷移式學習透過了Source & Target 在 instance 樣本、feature 特徵、parameter 參數、relation 關係…等移轉的手法讓 ML可以與時俱進,更加成熟地解決更多的挑戰。尤其是遇到愈來愈難取得個資的現代 Data set 取得挑戰,或是 Covid-19 影響人類的生活習慣讓之前已經生成好的模型,除了重新收集 data 並重新訓練之外,也有其他比較省時省力的作法…
實作:
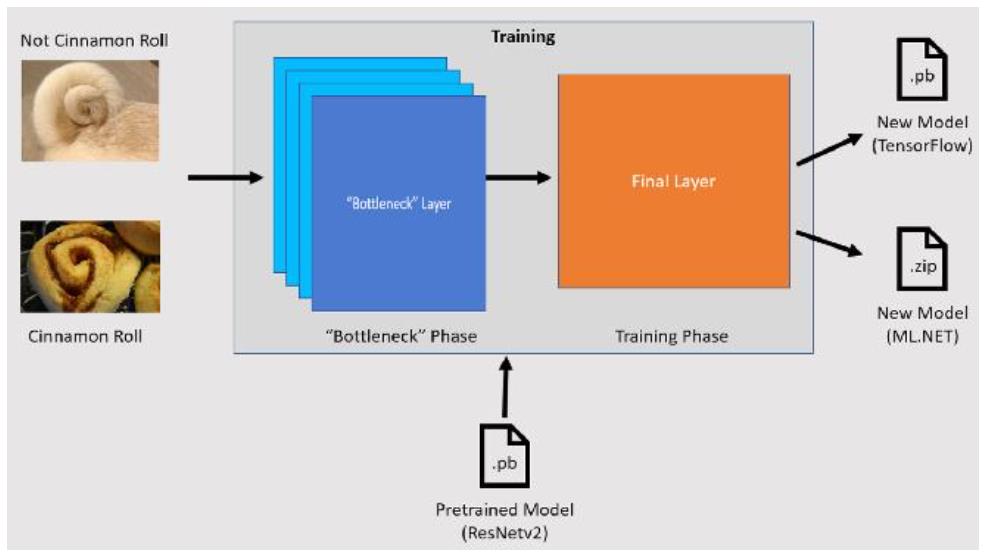
既然是初體驗,我們就從 Fine tuning開始,以下的範例我將採用 Keras的 Applications API,以近300張15個類別的建築物辨識題目,來做遷移式學習的 demo。但礙於篇幅有限,就不再贅述 Python code 中載入函式庫、調整GPU參數、讀取圖片、前處理,直接幫大家劃重點在 Transfer learning的細節(下面的理論圖解我是取自人工智慧學校 AIA的文章)
- 載入 Pre-trained Model:
不管在什麼時代,站在巨人的肩膀一直都是相當直觀且高效的作法,2006年李飛飛教授所創立的 Imagenet,經過多年的累積,已經超過了1400萬張照片(Multiple labeled),被分類在2萬個類別,十多年來這個 Image recognition題目的武林大會,吸引了多少的全球知名的學者、高手,一直到科技巨擘都躬逢其盛,讓 AI在影像辨識可以落地到民生的應用(例如,大約五年前當辨識率達到 95%台灣的大部份停車場都開始採用,來節省人力,加速車輛通過的時間)
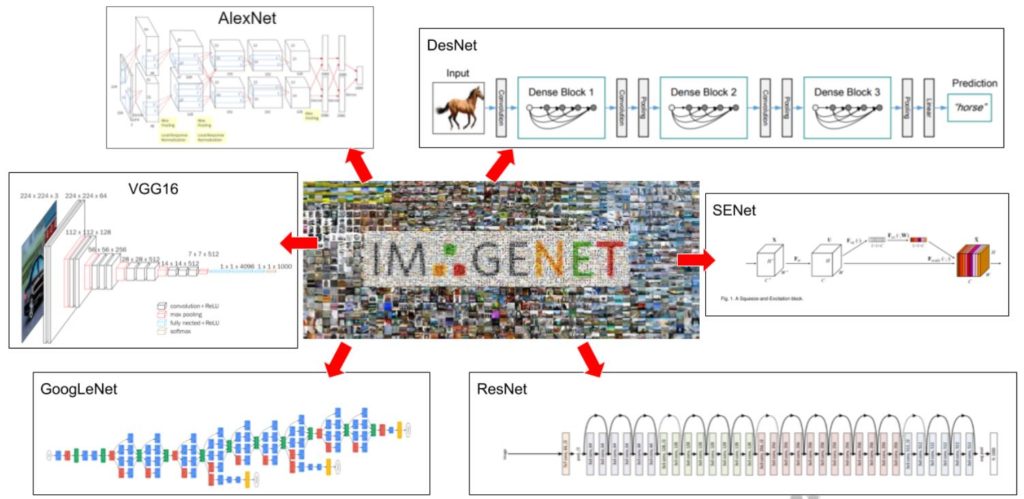
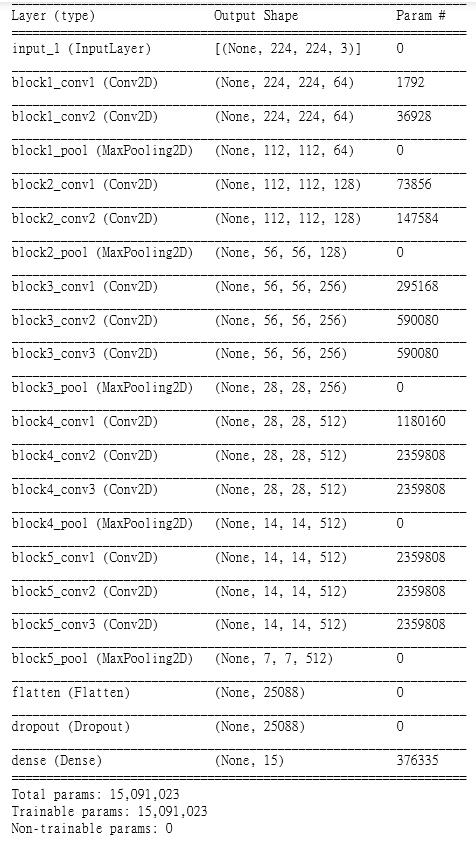
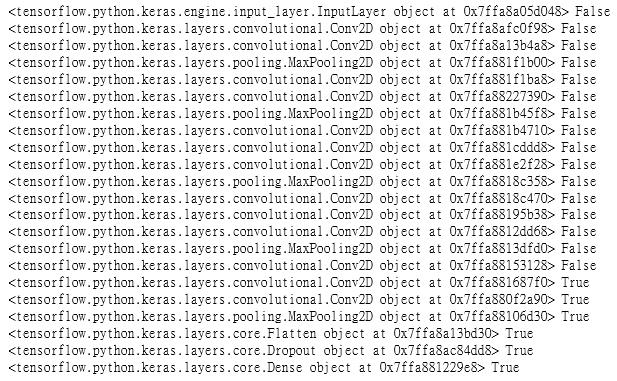
我們來看一下程式碼的部份:目前 Keras已經提供了25個武林大會中得名的模型,故,我載入了入門的16層的 VGG16,並且透過 Weights = ‘imagenet’ 來得到高手的參數值,include_top = false 在模型的最左邊(全連接層)中,當我要換成自己的圖片,就要這樣設定。接著,就是標準的 CNN 模型設定,細節可以參考之前的文章。用 summary() 預覽一下模型的樣貌與參數數量
其中有一個 Flatten() 是在建CCN模型中,常用於尾聲要把 Convolution 卷積層再接到全連接層,要做 Softmax 預測時的一個手法過程…

- 決定 Pre-Train 參數量:
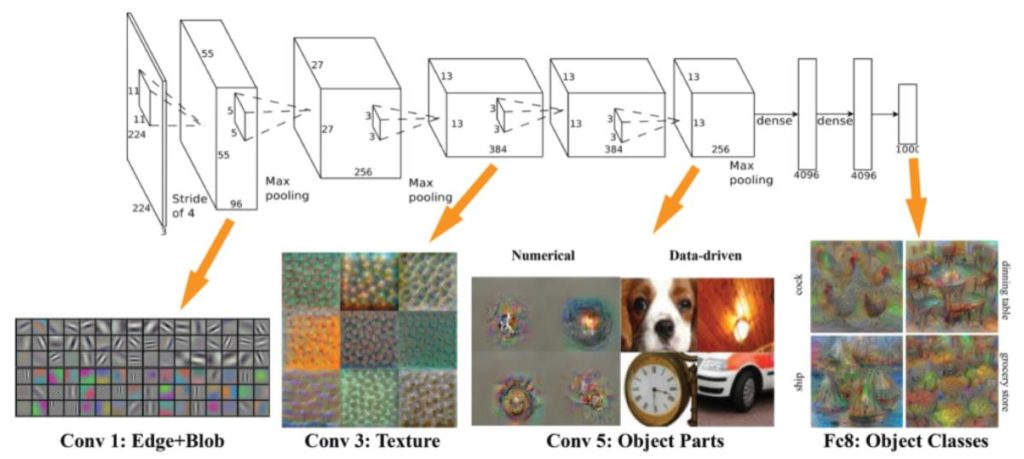
我們要捲起袖子進行凍結參數的動作,在開始之前,要先知道一個穩定的模型其 Learning rate已經達到最佳化了,重新訓練時會有 over fiting的風險。在下圖中,你可以看到CNN在低階層(左邊)時,還在學習點、線、邊緣…這個嬰兒級的常識,到了高階層(右邊)時,才能學習許多小物件併湊出來的的生物或物體。
依據 Source/ Target 資料集的相似度,你有以下的選擇:
A. 如果你的資料集並不大,當二個資料集比較相似時,只需遷移高階層的參數,以微調的方式,讓 Learning rate 控制在比較小;同理,當二個資料集比較不相似時,也只需要遷移低階層的參數,即可。
B. 如果你的資料集夠大,如果二個資料集比較相似時,你可以將 Pre-Train 模型的權重當作起始值,全部再訓練過一次,只是 Learning rate 比較大;如果二個資料集比較不相似時,你可以略過 Pre-Train model 自己來
以本文的案例來說,由於 Source/Target 的資料集相似,所以我就凍結大部份的模型,只重新訓練高階層的 3層,先設定 trainable = True,trainable_layer = 3,然後再用一個廻圈將其他階層凍結起來。最後,再印出來檢查一下…然後把其他模型訓練的超參數設定好,就準備要開始訓練了

- 開始訓練模型:
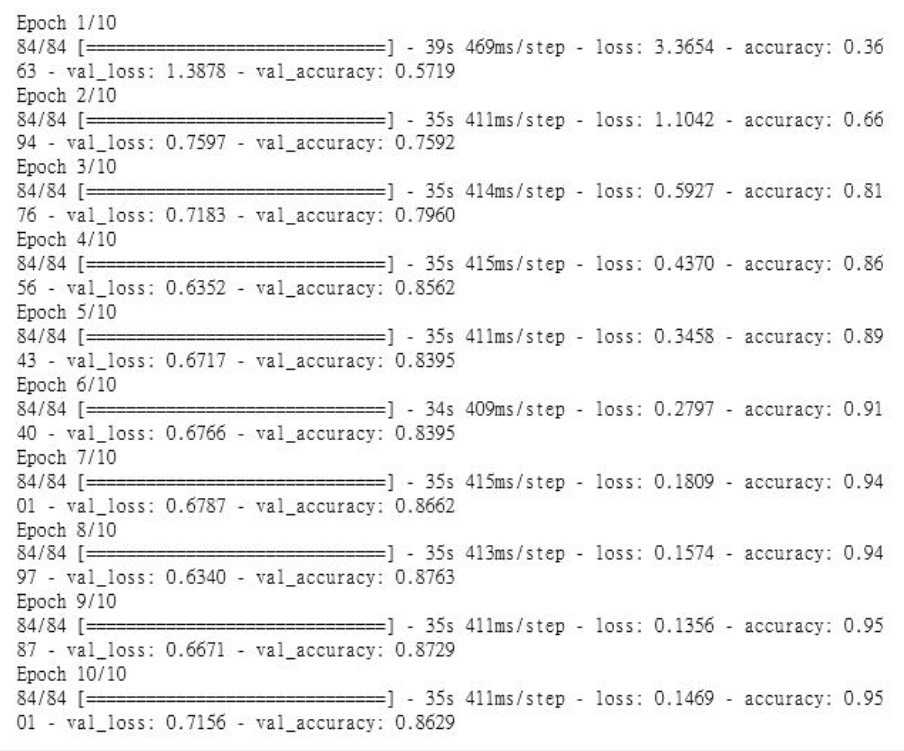
有了遷移式學習,只要經過10個 Epoches 正確率就可以達到 95%
- 視覺化訓練的結果:
接著我們就拿出近300筆的測試資料來驗證我們的模型吧!

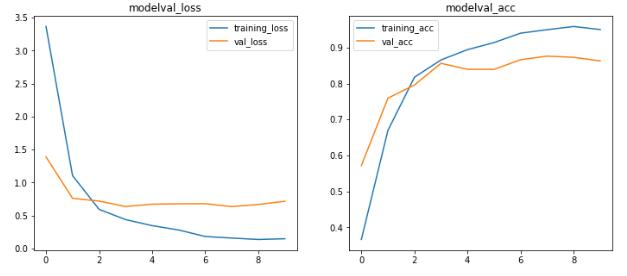
畫出訓練與測試階段的比較折線圖
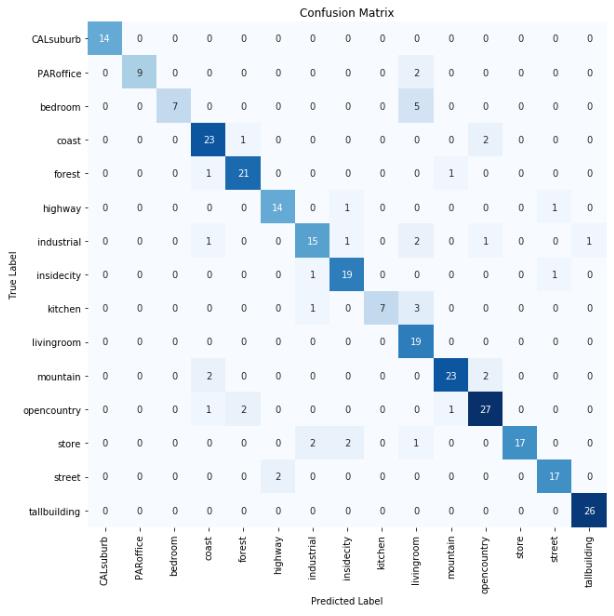
接著,再透過傳統與 Seaborn的混淆矩陣,了解測試時的錯誤分佈


Seaborn 的視覺化呈現效果好,適合拿來做報告
未來展望:
除了 Transfer learning之外,還有一個 Knowledge distillation 可以將具有眾多參數的大型 AI 模型,抽出精華,對小型的 AI模型做典範移轉。這裡有二個層面需要考量,一個是 AI如何落地?一個是如何因才施教?前者是,不可能隨時能夠搬一個 GPU 機櫃在路上走,或是你的產品內建有 Wifi 或是 5G行動上網能力,可以連結到雲端大型的 AI模型。後者是,當你的兒子終於過了強褓階段要上幼稚園,在他人生第一次的上學的經典斷捨離場景中,你找一個大學教授來教育你的寶貝,由於教授並不擅長處理一哭二鬧三上吊的小小孩反應。還不如找一個三十初頭的幼稚園主任,來的適合。因為像是 GPT-2 這種擁有上億參數等級的獨角獸大模型,你是很難直接放在你的手機中,會需要像是知識蒸餾這類的手法,才能成功落地的。將來有機會再來介紹給各位…
發佈日期 : 2021-03-04
本文經合作夥伴 授權轉載自 Transfer learning 初體驗 (Christian Lee)